
Introduction: AI Is No Longer Optional
Artificial Intelligence has moved from being a specialized skill to becoming a core part of modern software development. In 2026, an AI/ML Engineer is not just someone who trains models. The role now includes designing complete systems, handling data pipelines at scale, deploying models to production, and building real products that people use every day.
This shift has fundamentally changed how learning works. It is no longer enough to understand algorithms in isolation or to read research papers without applying them. The real value comes from connecting data, models, and systems into something useful, scalable, and maintainable over time.
The path forward is clear but not simple. You need to know what to study, how deeply to go into each area, and what to build along the way. This roadmap covers every stage with precision.
The Biggest Shift in AI Careers
A few years ago, knowing how to call a pre-trained model or complete a Kaggle challenge was enough to stand out. That baseline has moved significantly. Today, companies expect engineers who can operate across the full lifecycle of an AI system.
Working with Real-World Data Pipelines: You should be comfortable handling messy datasets, missing values, inconsistent formats, and large volumes of data. This includes building reliable pipelines that can feed both training and production systems without breaking under scale or changing data conditions.
Designing Complete AI Systems, Not Just Models: Modern AI work involves integrating models into real applications. This means understanding APIs, backend architecture, and how AI interacts with user-facing features in a live product environment where reliability matters.
Deploying and Maintaining Models in Production: Building a model is only part of the job. You must know how to deploy it, monitor its performance over time, detect drift, and update it when data distributions or business requirements change in the real world.
The defining difference in 2026 is not knowledge alone. It is execution. Companies are looking for engineers who can take an idea from a notebook all the way to a product that users depend on.
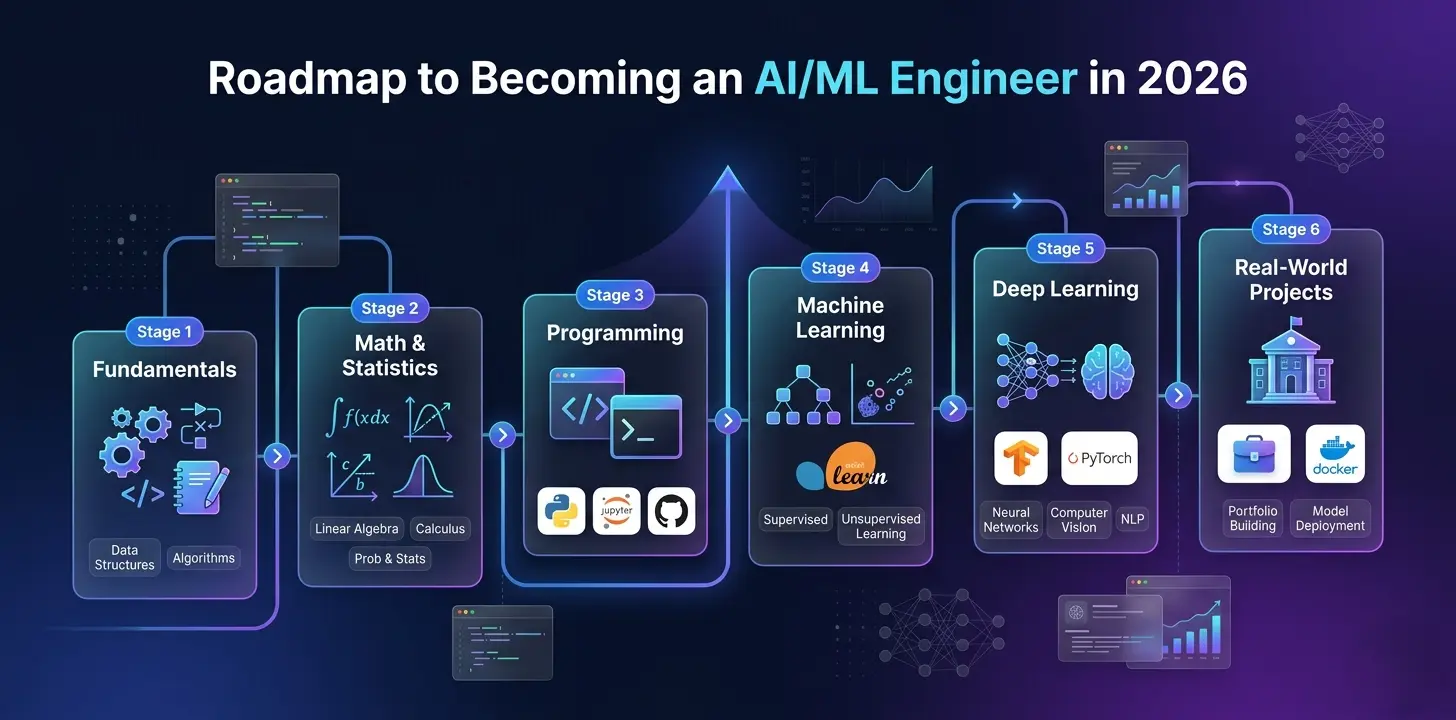
Step 1: Build Foundations That Do Not Break
Before jumping into frameworks and modern tools, strong fundamentals are necessary. Skipping them creates gaps that show up later when systems fail, models behave unexpectedly, or you cannot debug what is going wrong.
Mathematics for Intuition
Focus on understanding concepts rather than memorizing formulas. The goal is to build intuition that helps you reason about models and their behavior.
Linear Algebra: Learn how vectors and matrices represent data and transformations. Understand how matrix multiplication works because it is the backbone of neural networks and almost every machine learning operation. Every forward pass through a neural network is fundamentally a series of matrix multiplications.
Probability and Statistics: Study distributions, expectation, and variance to understand uncertainty in predictions. Concepts like Bayes theorem help explain how models update beliefs based on new data. You must understand how a model assigns confidence to its outputs and how to interpret those numbers meaningfully.
Calculus and Optimization: Focus on derivatives and gradients, which are used to optimize models during training. Understanding the chain rule is especially important because it explains how deep learning models learn through backpropagation.
Depth to Reach: You should be able to explain these ideas in simple language and understand their role in machine learning. You do not need to derive everything from scratch, but you must understand how each concept applies when a model behaves in unexpected ways.
Programming Skills That Match Real Work
Python is the standard language for AI and ML, but real-world work goes far beyond syntax.
Core Programming and Problem Solving: You need strong control over data structures, algorithms, loops, functions, and object-oriented programming. Writing clean and maintainable code is essential because AI systems grow complex quickly and must be readable by others.
Handling Real-World Data and Systems: Learn to work with APIs, files, and databases. Real datasets are rarely clean, so you must handle missing values, inconsistencies, encoding issues, and large-scale data processing efficiently without losing reliability.
Libraries and Ecosystem: Tools like NumPy, Pandas, and Matplotlib are not optional. They form the foundation for data manipulation, analysis, and visualization in almost every AI workflow. Mastering them means working faster and with fewer errors.
Depth to Reach: You should be able to write production-level scripts, debug issues independently, and optimize performance when dealing with large datasets that cannot fit into memory.
Step 2: Machine Learning Is Your Foundation, Not Your End Goal
Classical machine learning still solves a large portion of real business problems. It is the foundation you build everything else on, but it is not the destination.
What to Learn
Core Supervised Learning Algorithms: Learn linear and logistic regression to understand how models make predictions from input data. These algorithms build your intuition for how inputs are transformed into outputs through learned weights and decision boundaries.
Tree-Based and Ensemble Methods: Decision trees, random forests, and gradient boosting methods like XGBoost help you understand non-linear relationships and achieve strong performance in many real-world tabular data tasks. These remain widely used in industry.
Unsupervised Learning Techniques: Clustering methods like K-Means help you explore data patterns when labels are not available, which is common in practical scenarios like customer segmentation or anomaly detection.
What to Deeply Understand
Bias, Variance, and Overfitting: These concepts explain why models fail and how to improve them. A model that perfectly memorizes training data will perform poorly on new data. Understanding this trade-off helps you build models that generalize well to unseen examples through techniques like regularization.
Feature Engineering: The quality of input data often matters more than the choice of model. You should know how to create meaningful features from raw data, encode categorical variables, handle outliers, and transform distributions to improve model performance.
Model Selection and Performance Trade-Offs: You should know when to use a simple interpretable model and when a complex ensemble is needed, based on the nature of the data, the business problem, and the constraints around deployment.
Depth to Reach: You should be able to train, tune, and evaluate models while clearly explaining how and why they work, what their assumptions are, and where they will fail.
Model Evaluation: Beyond Accuracy
In 2026, an engineer who only looks at accuracy is considered a beginner. Metrics define whether your model is genuinely useful or simply producing misleading numbers.
Precision, Recall, and F1 Score: Accuracy alone is not enough, especially when class imbalance exists. In fraud detection, a false negative (missing a fraudulent transaction) is far more costly than a false positive (flagging a legitimate one). You must understand the business cost of each type of error and choose your metric accordingly.
ROC-AUC and Cross-Validation: These techniques help you evaluate models more reliably and avoid results that look good only on training data. ROC-AUC measures how well your model distinguishes between classes across all decision thresholds.
Choosing the Right Metric for the Problem: Different problems require completely different evaluation strategies. A model for medical diagnosis, a recommendation engine, and a churn predictor each require different success criteria. Knowing which metric to prioritize is a skill that separates engineers from researchers.
Depth to Reach: You should confidently interpret model performance, explain results in business terms, and know when a seemingly strong model is actually inadequate for the problem it is meant to solve.
Step 3: Deep Learning Is Mandatory
In 2026, most advanced AI systems are powered by deep learning. You must move beyond classical algorithms and understand how modern neural networks are built, trained, and applied at scale.
Core Concepts
Neural Networks and the Learning Process: Understand how layers of neurons process data and how weights are adjusted during training through gradient descent. This forms the conceptual base for all deep learning systems.
Activation and Loss Functions: These control how models learn and how errors are measured during training. Choosing the right activation function for the output layer and the right loss function for the task directly impacts what the model learns to optimize.
Backpropagation and Optimization: Learn how gradients flow backward through the network and how optimizers like Adam or SGD update weights efficiently during training.
Architectures to Know
CNNs for Visual Data: Convolutional Neural Networks are used for image recognition, object detection, and similar tasks where spatial patterns in data matter. Understanding their structure helps you apply them to custom vision problems.
Transformers as the Industry Standard: Transformers have replaced RNNs and LSTMs as the dominant architecture for sequence data and now power almost every major AI system. The core self-attention mechanism allows the model to selectively focus on the most relevant parts of an input, regardless of position:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Understanding this equation is not optional. It is the foundation of every modern language model and multimodal system.
Depth to Reach: You should be able to build, train, and debug models using frameworks like PyTorch, understand the design decisions behind each architecture, and know how to adapt pre-trained models to new tasks.
Step 4: LLMs and the Generative Revolution
Large Language Models have shifted AI from predicting outputs to generating content and reasoning through complex tasks. In 2026, you are not just using LLMs. You are building complete systems around them.
What to Learn
Transformer Architecture and Attention in Depth: Understanding how models process context and maintain relationships across long sequences is essential. This knowledge is what allows you to debug hallucinations, improve response quality, and design effective prompting strategies.
Prompt Design and Context Management: Writing effective prompts goes far beyond simple instructions. You must master chain-of-thought reasoning, few-shot prompting, and managing conversation memory to build AI systems that behave reliably across varied inputs.
Embeddings and Vector Search: These are the foundation of modern AI memory systems. Understanding how to convert text, images, or any structured data into high-dimensional vectors enables semantic search, recommendation systems, and RAG pipelines that give models access to accurate, real-time information.
RAG (Retrieval-Augmented Generation): Connecting LLMs to private vector databases like Pinecone allows you to give models access to company-specific or domain-specific knowledge without retraining. This is one of the most commercially valuable skills in the field.
Tools That Matter
Hugging Face: Provides access to thousands of pre-trained models and tools for fine-tuning, evaluation, and experimentation across text, vision, and audio tasks.
OpenAI and Anthropic APIs: Enable you to build powerful AI applications without training massive models from scratch. Understanding how to use these APIs efficiently, including function calling and structured outputs, is practically essential.
LangChain and LlamaIndex: Help you connect models, data sources, memory, and logic into complete AI systems that can reason, retrieve information, and execute multi-step tasks.
Depth to Reach: You should be able to design and build full applications powered by LLMs, not just simple demos. This includes handling failure cases, managing costs, and ensuring outputs are reliable enough for production use.
Step 5: Data Engineering Basics
AI systems are only as good as the data flowing into them. Data engineering is not a separate specialization; it is a core part of the AI engineer's skill set.
Structured Data Management with SQL: Learn how to query, filter, join, and aggregate data efficiently. Most real-world data lives in relational databases, and the ability to extract exactly what you need without loading everything into memory is a fundamental skill.
Data Cleaning and Preprocessing: Raw data is rarely usable. You must be able to handle missing values, remove duplicates, normalize formats, encode categorical variables, and transform distributions into forms suitable for model training. This work often takes more time than the modeling itself.
Building Automated Pipelines: Learn how to automate data collection, transformation, validation, and storage for consistent and repeatable workflows. A pipeline that requires manual intervention every time it runs is not a production pipeline.
NoSQL and Unstructured Data: Understand when to use document stores, key-value databases, or vector databases. Unstructured data including text, images, and logs makes up a significant portion of what modern AI systems process.
Depth to Reach: You should be comfortable handling large datasets and preparing them for machine learning tasks without significant manual effort each time the pipeline runs.
Step 6: MLOps — The Professional Divider
MLOps is what separates engineers who build things that work once from those who build things that work reliably over time. A model that lives only in a notebook has zero business value.
Model Deployment as APIs: Learn to serve models using tools like FastAPI so they can be used by applications in real time. This includes handling concurrent requests, managing latency, and returning structured responses that downstream systems can consume.
Containerization and Environment Management: Docker ensures your model runs consistently across different systems and environments. If it works on your machine but fails in the cloud, it is not ready for production.
Monitoring and Drift Detection: Models degrade over time as the real-world data they receive changes. You must know how to monitor performance metrics continuously, detect when a model has drifted from its training distribution, and trigger retraining or alerting accordingly.
Experiment Tracking and Versioning: Tools like MLflow allow you to log parameters, metrics, and artifacts from every training run. This makes it possible to reproduce results, compare experiments, and understand exactly what changed between model versions.
Cloud Platforms and Scaling: Understand how to deploy systems on AWS SageMaker or Google Vertex AI and scale them based on real usage patterns. Local deployment is a stepping stone, not the destination.
Depth to Reach: You should be able to deploy, monitor, and maintain a complete AI system in a real cloud environment, including handling failures gracefully and updating models without downtime.
Step 7: Projects That Actually Build Your Career
Projects define your ability more than any certificate or course completion. Skip the Titanic dataset and MNIST. They were useful in 2019. In 2026, they signal that you have not moved forward. Build things that solve real problems and demonstrate complete systems.
Beginner Level
House Price Prediction System: Focus on cleaning real estate data, selecting meaningful features like location, size, and age, and building a regression model that produces interpretable outputs. The goal is to practice the full data-to-model pipeline.
Spam Email Classifier: Learn basic natural language processing and classification techniques. Understand how text data is vectorized, how models distinguish signal from noise, and how to evaluate performance on imbalanced classes.
Intermediate Level
Customer Churn Prediction System: Work with realistic business datasets, apply feature engineering on behavioral and transactional data, and compare multiple models to understand performance differences in a context where the cost of false negatives is real.
Image Classification Application: Build a CNN-based model using a custom dataset. Go beyond using pre-built examples and understand how image data is preprocessed, augmented, and fed through convolutional layers.
Recommendation System: Implement both collaborative filtering and content-based approaches. Understand how modern platforms suggest content and measure recommendation quality beyond simple accuracy.
Advanced Level
LLM-Powered Chat Application: Build a chatbot with persistent memory, context awareness, and RAG integration using a vector database. The system should handle multi-turn conversations and retrieve accurate information from a private knowledge base.
AI SaaS Product: Create a tool that solves a real user problem — a resume analyzer, an AI writing assistant, or an automated research summarizer. The focus is on building something someone would actually pay to use.
End-to-End ML Pipeline: Build a full system including data ingestion, automated preprocessing, model training, deployment via API, and monitoring. Document every stage and make it reproducible.
Expert Level
Multimodal AI System: Combine text, image, and audio processing into a single system that handles complex real-world inputs. This requires understanding how different data types are encoded and how models are aligned across modalities.
Real-Time AI System: Build a system that processes and responds instantly, such as a fraud detection engine or a live recommendation feed. This requires understanding latency constraints, streaming data, and low-latency model serving.
Autonomous AI Agent: Develop an agent that can plan, decide, and execute multi-step tasks independently. For example, a travel planning agent that searches for flights, checks prices via API, compares options, and drafts a summary — without manual intervention at each step.
Step 8: The 2026 Tool Stack
To be competitive in 2026, your tool stack must span the full lifecycle of an AI system.
Core Development: Python remains the foundation. Strong knowledge of data handling libraries, asynchronous patterns, and backend integration is expected at every level.
Deep Learning and Model Tools: PyTorch is the standard framework for building and training models. Hugging Face provides access to pre-trained models and simplifies fine-tuning workflows across all modalities.
Application and API Tools: FastAPI for model serving, LangChain or LlamaIndex for building LLM-powered pipelines, and OpenAI or Anthropic APIs for accessing frontier models without training from scratch.
Deployment and Infrastructure: Docker for containerization, MLflow for experiment tracking, and GitHub Actions or similar tools for CI/CD pipelines that automate testing and deployment.
Cloud Platforms: AWS SageMaker and Google Vertex AI provide managed environments for training at scale, deploying endpoints, and monitoring production models. Familiarity with at least one is expected.
Advanced Infrastructure: Pinecone or Weaviate for vector databases, Redis or Kafka for real-time data streaming, and Prometheus or Grafana for system monitoring at production scale.
Common Mistakes to Avoid
Focusing Only on Theory: Reading papers and watching lectures without building projects leaves knowledge incomplete and difficult to apply. Theory without implementation leads to what engineers call tutorial hell — learning without growing.
Copying Code Without Understanding: This limits your ability to debug and adapt when you encounter a new problem. If you cannot explain every line of your implementation, you cannot fix it when something breaks in production.
Ignoring Deployment and System Design: Real AI work happens in production, not in Jupyter notebooks. A model that has never been deployed is a model that has never been tested against reality.
Avoiding Modern AI Tools: Skipping LLMs, vector databases, and current orchestration frameworks will make your skillset outdated quickly. The tools used in production today are significantly different from those of even two years ago.
Staying at Beginner Projects: Growth requires moving into complex, real-world systems that solve meaningful problems. If every project you build is something with a known tutorial, you are not developing genuine problem-solving ability.
Skipping Documentation and Reproducibility: In professional environments, a model that cannot be reproduced or explained is a liability. Good engineers document decisions, version their data, and make their work understandable to others.
Final Roadmap: Your 2026 Execution Plan
Month 1–2: Foundations Learn Python deeply and build mathematical intuition in linear algebra, probability, and calculus. Complete small programming projects that reinforce data handling and clean code practices.
Month 3–4: Classical Machine Learning Work through supervised and unsupervised learning algorithms. Build and evaluate models on real datasets. Focus on understanding bias-variance trade-offs and feature engineering before moving forward.
Month 5–8: Deep Learning and Transformers Learn neural network fundamentals, train CNNs on vision tasks, and study transformer architecture in depth. Build at least two projects that involve training models from scratch and fine-tuning pre-trained ones.
Month 9–12: LLMs, MLOps, and Capstone Project Build LLM-powered applications with RAG and memory. Learn to deploy, monitor, and maintain models in a cloud environment. Complete one expert-level capstone project that demonstrates the full stack from data to deployed product.
Conclusion: The Era of the AI Builder
In 2026, the AI/ML Engineer is no longer just a model trainer or a researcher. The role has expanded into creating full-scale intelligent systems that reason, retrieve information, act on instructions, and evolve with changing data. It is one of the most demanding and most rewarding roles in modern technology.
Those who succeed will be the ones who combine strong mathematical foundations with practical deployment skills, who build real products instead of just running notebooks, and who stay current with a field that continues to move faster than any other.
The opportunity to build systems that genuinely change how people work and live is larger than it has ever been. The roadmap is in front of you. The only variable is whether you start building today.
AI is not just something you learn. It is something you build with.